프롬프트 다음, 컨텍스트 다음은 ‘하네스’다 — Agent Harness Engineering 서베이 정리
LLM 에이전트가 실제 프로덕션에서 신뢰성 있게 동작하는 이유는 모델이 좋아져서가 아니라, 모델을 감싸는 “하네스(harness)“가 잘 짜여져 있어서다.
2026년 5월 16일 공개된 Agent Harness Engineering: A Survey (Li et al., 20인 공저)는 이 직관을 정면으로 다룬 첫 번째 본격 서베이다. 170개 이상의 오픈소스 프로젝트를 ETCLOVG라는 7계층 분류로 매핑하고, 하네스를 모델 옆에 두는 보조 코드가 아니라 독립적인 시스템 계층으로 정립한다.
이 글은 그 서베이를 우리 개발자의 시각에서 압축해 정리한다.
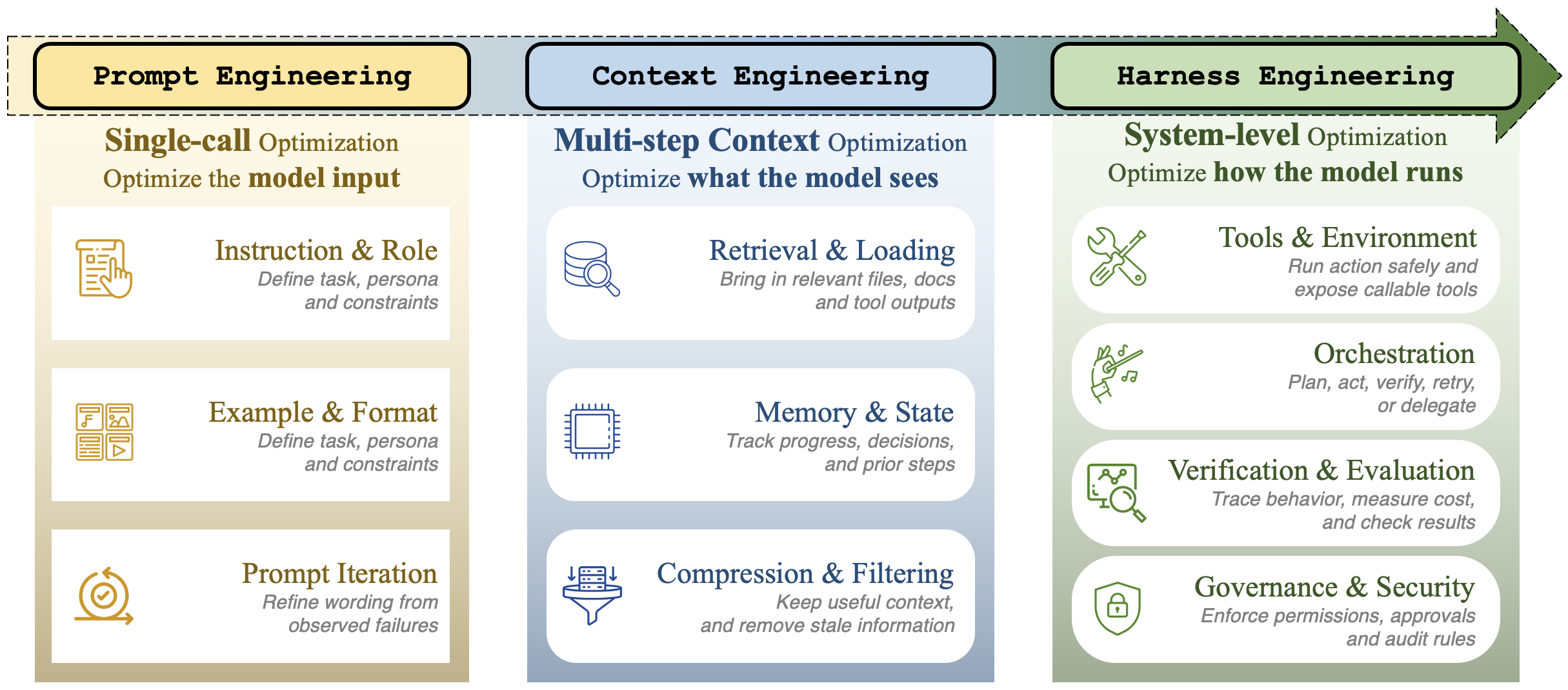 Prompt Engineering → Context Engineering → Harness Engineering 으로의 진화. 단일 호출 입력 → 모델이 보는 것 → 모델이 실행되는 방식 자체로 관심사가 이동했다. (출처: picrew.github.io/LLM-Harness)
Prompt Engineering → Context Engineering → Harness Engineering 으로의 진화. 단일 호출 입력 → 모델이 보는 것 → 모델이 실행되는 방식 자체로 관심사가 이동했다. (출처: picrew.github.io/LLM-Harness)
1. 왜 지금 “하네스 엔지니어링”인가
지난 4년 동안 우리가 “AI 앱”을 만드는 방식은 한 단계씩 추상화 수준이 올라왔다.
| 기간 | 단계 | 주된 레버 (primary lever) |
|---|---|---|
| 2022–2024 | Prompt engineering | 단일 호출에 들어가는 입력 텍스트 — 지시, 페르소나, few-shot, reasoning template |
| 2025 | Context engineering | ”각 단계에서 모델이 무엇을 보아야 하는가?” — retrieval, compaction, tool-result ranking |
| 2026– | Harness engineering | 실행 환경 · 도구 · 컨텍스트 · 라이프사이클 · 관측 · 검증 · 거버넌스 전체 인프라 래퍼 |
저자들의 말을 그대로 옮기면 이렇다.
Real-world reliability is shaped by execution controls, feedback loops, governance, evaluation, and operational design — not only by model capability.
즉, “어떤 모델을 쓸까”보다 “모델 주변에 어떤 시스템을 두를까”가 더 큰 변수가 되었다는 것이다.
이미 우리는 이걸 경험적으로 알고 있다. 2026년 4월 LangChain은 모델은 gpt-5.2-codex로 고정해 두고 하네스만 바꿔서 Terminal Bench 2.0 점수를 52.8 → 66.5점 (+13.7점)으로 끌어올렸다 (LangChain 블로그). 모델은 그대로인데 점수가 13점 오른다는 건, 거기에 그만큼 큰 설계 공간이 숨어 있다는 뜻이다.
서베이는 그 설계 공간을 처음으로 정면으로 지도화한다.
2. ETCLOVG — 하네스를 7계층으로 자르기
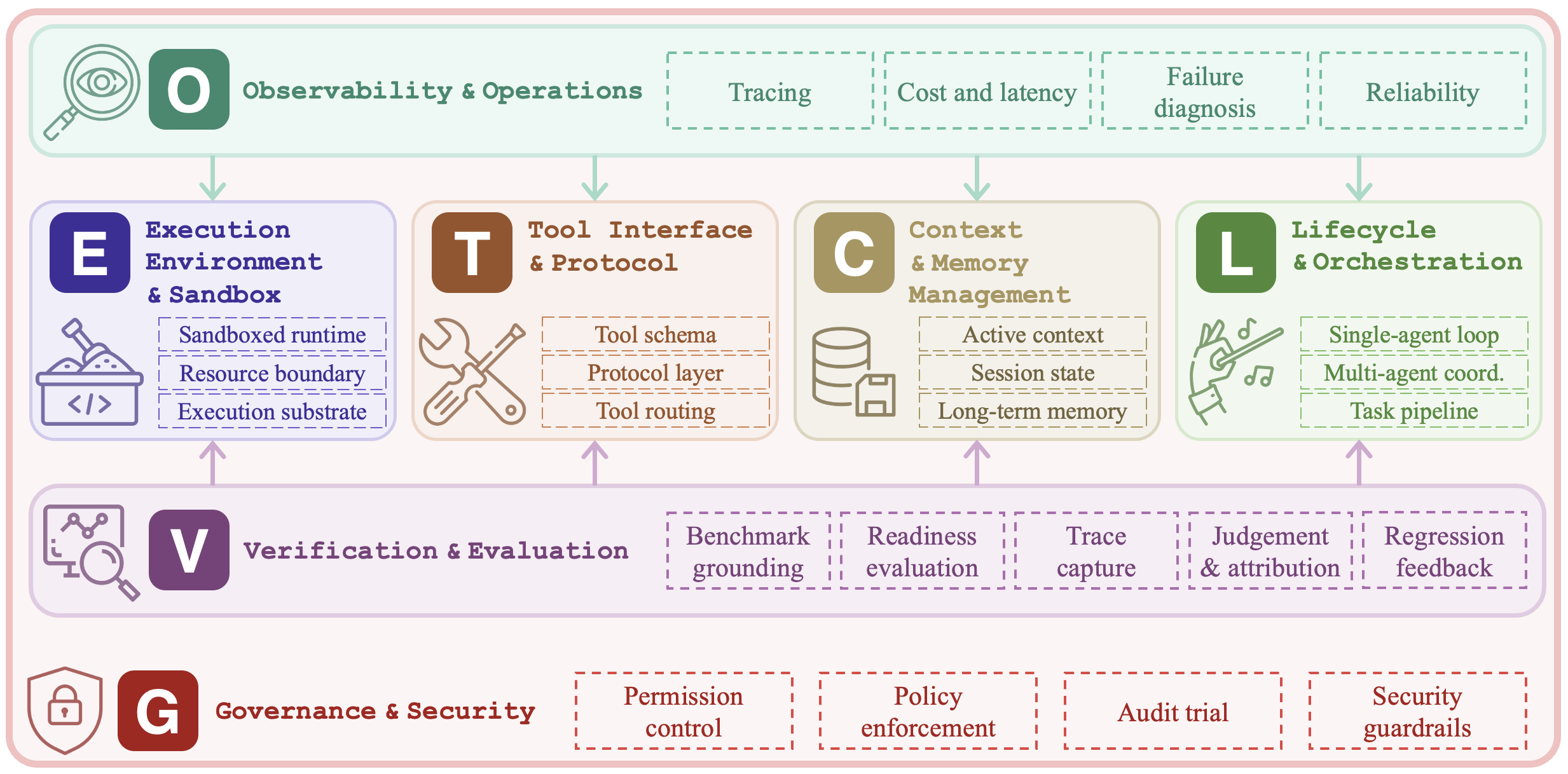 ETCLOVG 7계층 분류. 기존 6-컴포넌트 프레임워크들이 뒤섞었던 관심사를 7개로 분리하면서, 특히 O(관측 가능성) 과 G(거버넌스) 를 독립 계층으로 승격한 것이 핵심. (출처: picrew.github.io/LLM-Harness)
ETCLOVG 7계층 분류. 기존 6-컴포넌트 프레임워크들이 뒤섞었던 관심사를 7개로 분리하면서, 특히 O(관측 가능성) 과 G(거버넌스) 를 독립 계층으로 승격한 것이 핵심. (출처: picrew.github.io/LLM-Harness)
서베이의 핵심 기여 중 하나는 ETCLOVG라는 7글자 분류법이다.
| 코드 | Layer | 한국어 의미 | 주요 관심사 |
|---|---|---|---|
| E | Execution environment | 실행 환경 / 샌드박스 | 컨테이너, microVM, OS 권한 경계, 브라우저 환경 |
| T | Tool interface & protocol | 도구 인터페이스 · 프로토콜 | tool schema, MCP, A2A, function calling |
| C | Context & memory management | 컨텍스트 · 메모리 | retrieval, compaction, long-term memory |
| L | Lifecycle & orchestration | 라이프사이클 · 오케스트레이션 | 단일/멀티 에이전트 루프, task pipeline |
| O | Observability & operations | 관측 가능성 · 운영 | tracing, cost/latency, failure diagnosis |
| V | Verification & evaluation | 검증 · 평가 | 벤치마크, regression feedback, trace capture |
| G | Governance & security | 거버넌스 · 보안 | 권한 제어, 정책, 감사 추적, security guardrails |
기억해야 할 포인트: 기존 프레임워크들은 보통 “도구 + 메모리 + 루프 + 평가”의 4~6 컴포넌트 정도로 끊었다. 이 서베이는 거기에 관측(O) 과 거버넌스(G) 를 별도 계층으로 분리했다. 둘 다 프로토타입에서는 잘 보이지 않지만, 프로덕션으로 넘어가는 순간 결정적인 요소가 된다.
2.1 분포 통계 — 어디에 빈 곳이 있나
170개 이상의 오픈소스 프로젝트를 ETCLOVG에 multi-label로 매핑한 결과:
| Layer | 1차(primary) 프로젝트 수 |
|---|---|
| L — Lifecycle & orchestration | 47 🥇 |
| V — Verification & evaluation | 21 |
| E — Execution environment | 20 |
| O — Observability & operations | 15 |
| G — Governance & security | 14 |
| T — Tool interface & protocol | 12 |
| C — Context & memory management | 9 |
이 분포가 그 자체로 흥미로운 진단이 된다.
- 밀도 높음(E, T, L, V): 코딩/웹/터미널 에이전트가 table-stakes로 요구하는 것들이다. 샌드박스, 도구 계약, 제어 루프, 반복 평가가 없으면 시작조차 못 한다.
- 숨겨져 있음(C): 컨텍스트/메모리는 많은 프로젝트에 등장하지만 독립 컴포넌트보다 큰 프레임워크에 내장되어 출시되는 경우가 많다. 그래서 카운트가 작아 보일 뿐이다.
- 얇음(O, G): 오픈소스에서 제일 덜 익은 영역. 운영 통제(operational control)는 런타임이나 벤치마크보다 한참 뒤에 성숙한다. 거꾸로 말하면, 이쪽은 아직 빈 자리가 많다.
3. 하네스의 짧은 역사 — ReAct부터 2026년까지
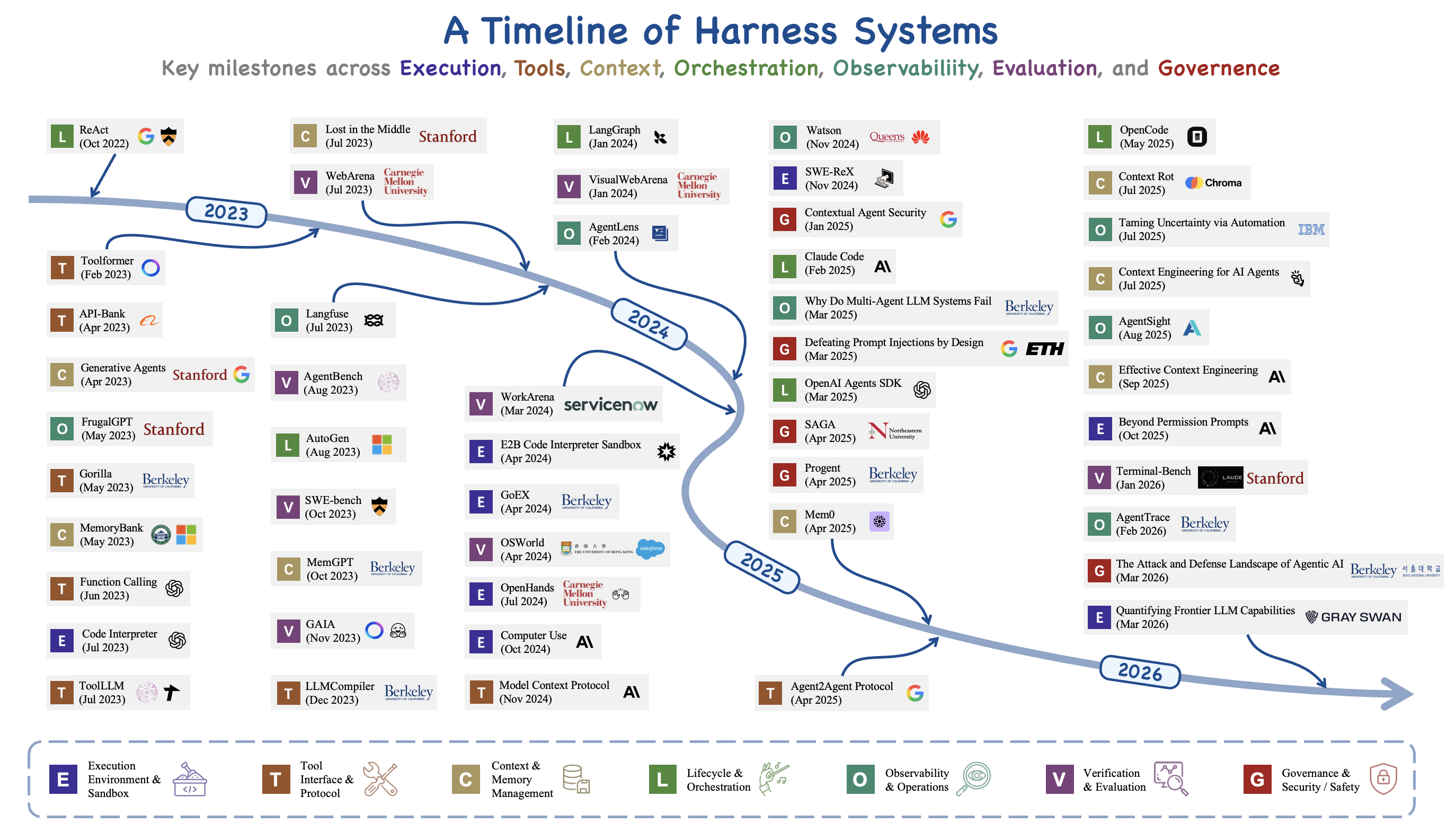 2022~2026 하네스 시스템의 주요 마일스톤. ReAct, Toolformer, Function Calling 같은 초기 발자국부터 SWE-bench, MCP, AgentGym, Terminal-Bench, Frontier LLM Capabilities까지. (출처: picrew.github.io/LLM-Harness)
2022~2026 하네스 시스템의 주요 마일스톤. ReAct, Toolformer, Function Calling 같은 초기 발자국부터 SWE-bench, MCP, AgentGym, Terminal-Bench, Frontier LLM Capabilities까지. (출처: picrew.github.io/LLM-Harness)
2022–2023 — ReAct era
처음의 하네스는 단순했다. while 루프 + 프롬프트 템플릿 + 작은 tool dispatch table. ReAct가 그 원형이다.
곧 AutoGPT, BabyAGI 같은 시도가 등장하면서 새로운 종류의 실패가 드러난다 — 실행 폭주(execution runaway), 컨텍스트 폭발(context blowout), 상태 손실(state loss), 부작용 미관측. 이때부터 사람들은 깨닫는다. 이건 프롬프트 문제가 아니라 인프라 문제다.
2023–2024 — 도구와 멀티에이전트
- 학습된 도구 사용 — Gorilla, ToolLLM, Toolformer
- 역할 기반 조직 — CAMEL, ChatDev, MetaGPT, Mixture-of-Agents
- 첫 벤치마크 — SWE-bench, AgentBench, WebArena, GAIA
- 프로토콜 표준화 시작 — MCP, A2A
이 시기에 “에이전트 = 단일 LLM + 도구” 패러다임이 굳어진다.
2025–2026 — Harness engineering으로 명명됨
모델이 몇 시간 단위 자율 작업을 시도할 만큼 강해지면서, 병목이 모델 안쪽에서 그 바깥의 시스템 전체로 옮겨간다.
이 흐름의 결정적인 한 방이 앞서 인용한 LangChain Deep Agents의 +13.7점 실험이다. 모델은 그대로, 하네스만 바꿔서 점수가 두 자릿수 오른다는 사실이 “harness engineering”이라는 명명을 정착시켰다.
4. 한 레이어로는 풀리지 않는 세 가지 시스템 제약
서베이의 진짜 통찰은 분류법 자체가 아니라 여러 레이어가 결합되었을 때 생기는 제약을 짚어낸 부분이다.
4.1 Cost–Quality–Speed Trilemma (비용·품질·속도 삼중고)
더 강한 샌드박스, 더 풍부한 컨텍스트, 더 깊은 평가는 품질을 올린다. 그러나 동시에 토큰·지연시간·인프라 비용도 같이 올린다.
→ 프로덕션 하네스는 “어떤 위험에 비싼 통제를 쓸지 / 어떤 점검은 비동기·회귀 스위트로 돌릴지”를 명시적으로 결정해야 한다. 품질을 단일 스칼라로 다루면 망한다.
4.2 Capability–Control Tradeoff (능력 vs 통제)
더 큰 도구 메뉴, 영속 메모리, 관대한 샌드박스 = 작업 커버리지 확대. 그런데 동시에 오정렬·침해 시 폭발 반경(blast radius)도 같이 커진다.
능력과 통제는 별개 축이 아니라 하나의 설계 축 위에 있다. 이 축은 tool schemas, context policy, runtime permissions, identity, auditability, human approval을 동시에 관통한다.
4.3 Harness Coupling Problem (하네스 결합 문제)
이게 가장 실용적으로 중요한 메시지다.
하네스 변경은 시스템 변경(system change)으로 테스트하라.
프롬프트·도구·샌드박스·검증기·모니터를 따로 따로 보면 좋아 보이는 변경이, 전체 제어 루프와 합쳐지면 롤아웃을 망가뜨릴 수 있다. 국소 최적화(local optimization)는 깨지기 쉽다.
이 결합 문제 때문에 자연스럽게 산업의 흐름이 한 방향으로 간다:
agent framework → agent platform
“에이전트/도구/메모리/실행 루프”라는 국소 추상화의 패키지에서, 여러 실행과 여러 사용자에 걸친 durable workspaces, identity, observability, evaluation, governance, human handoff까지 다루는 플랫폼으로의 이동.
5. 아직 열려 있는 5가지 문제
서베이가 마지막 장에서 짚는 5가지 open problem은 그대로 다음 1~2년의 R&D 로드맵에 가깝다.
-
Hardening and scaling execution environments
- 보안 평가 표준(prompt injection, goal misalignment, compositional amplification)
- containers vs microVMs vs OS permission boundaries vs full desktop VMs vs 브라우저 vs learned surrogates의 비용 모델
- self-hosted / cloud / hybrid 간 의미 보존 portability
-
Reliable state in long-running agents
- 컨텍스트 관리를 state estimation 문제로 재정의
- 압축 / 검색 / 망각 각 단계의 정보 손실 특성화
- provenance, contradiction handling, explicit staleness markers
- 압축 이력이 아니라 durable artifacts로부터 복원
-
Trace-native failure diagnosis
- 트레이스를 사후 디버깅이 아니라 outcome scores, trajectory quality, failure attribution, regression tests를 산출하는 1급 객체로 격상
- “광범위한 observability 채택”과 “드문 offline evaluation” 사이의 간극이 출발점이다
-
Standard handoffs across agents, tools, and humans
- 텍스트 요약만이 아니라 intent, constraints, permissions, artifacts, provenance, budget state, risk level, trace history, unresolved decisions까지 이양
- 안전·복구에 충분히 풍부하면서 광범위 채택될 만큼 단순한 프로토콜의 설계
-
Adaptive simplification as models improve
- 모든 래퍼는 “모델이 혼자 못 한다”는 가정을 인코딩한다
- 모델이 좋아질수록 일부 개입은 핵심으로 남고 일부는 불필요한 비용·지연·운영 부담으로 전락
- 미래의 하네스는 품질·지연·비용·위험을 공동 제약으로 두고 스스로를 ablate / optimize / simplify 하는 메커니즘이 필요
5번 항목은 Anthropic의 “가능한 가장 단순한 솔루션부터, 필요할 때만 복잡성을 늘려라” 원칙과 같은 방향을 가리킨다. 모델이 좋아질수록, 작년에 우리가 자랑하던 미들웨어들이 부담이 되는 때가 온다.
6. 그래서 우리는 무엇을 해야 하는가
이 서베이를 읽고 나면 자연스럽게 따라오는 실용적 함의가 몇 개 있다.
-
“모델만 바꾸자”는 거의 항상 잘못된 첫 번째 가설이다. 점수가 안 나오는 이유의 대부분은 모델이 아니라 그 주변 시스템에 있다. LangChain의 +13.7점이 그 증거다.
-
하네스를 7개 관심사로 끊고 점검하라. ETCLOVG는 좋은 체크리스트다. 특히 O와 G는 프로토타입에서는 잘 안 보이지만, “이 에이전트를 실제 운영에 올려도 되나?”라는 질문에 답할 수 있는 거의 유일한 레이어다.
-
하네스 변경은 시스템 테스트로 검증하라. A/B로 어느 한 미들웨어만 켜고 끄는 측정은 결합 문제 때문에 자주 잘못된 신호를 준다. 풀 trace + outcome score 단위로 본다.
-
카탈로그를 그냥 한 번 훑어라. 저자들이 운영하는 Picrew/awesome-agent-harness는 살아있는(living) 카탈로그다. ETCLOVG 카테고리별로 상위 3개씩만 훑어도 “내 하네스가 어디 빠져 있나”가 보인다.
7. 더 읽을거리
- 논문 본문: OpenReview
eONq7FdiHa· PDF - 프로젝트 페이지: picrew.github.io/LLM-Harness (위 이미지들의 출처)
- 오픈소스 카탈로그: Picrew/awesome-agent-harness (207 entries, PR로 갱신)
- 데이터셋: HuggingFace
ChenLiu1996/Agent-Harness-Engineering - 하네스만 바꿔서 +13.7점: LangChain — Improving Deep Agents with Harness Engineering
- 이 글의 원본 정리 노트: 2026-05-24-agent-harness-engineering-survey
Citation
@misc{li2026agentharness,
title={Agent Harness Engineering: A Survey},
author={Li, Junjie and Xiao, Xi and Zhang, Yunbei and Liu, Chen and
Zhao, Lin and Liao, Xiaoying and Ji, Yingrui and Wang, Janet and
Gu, Jianyang and Ge, Yingqiang and Xu, Weijie and Fang, Xi and
Xu, Xiang and Zhao, Tianchen and Kim, Youngeun and
Wang, Tianyang and Hamm, Jihun and Krishnaswamy, Smita and
Huan, Jun and Reddy, Chandan},
url={https://openreview.net/pdf?id=eONq7FdiHa},
year={2026}
}