Auto-review — 에이전트 행동의 비동기 자동 심사
OpenAI Alignment Blog의 “Auto-review of agent actions without synchronous human oversight” 한국어 번역본.
한 줄 요약
Auto-review는 코딩 에이전트가 샌드박스 경계를 넘는 행동을 요청할 때, 사람이 즉시 승인하는 대신 별도의 에이전트가 승인/거절을 판단하도록 만든 안전 기본값이다. 인간의 동기식 검토를 줄이면서도, 위험한 동작을 막을 수 있다는 점이 핵심이다.
배경: 왜 필요한가
기존 Codex에는 크게 두 가지 모드가 있었다.
- Default mode: 자주 사람 승인을 받아야 한다.
- Full Access mode: 마찰은 적지만, 샌드박스 보호가 사실상 사라진다.
OpenAI는 이 둘 사이의 중간 지점을 찾는다. 인간 승인을 너무 자주 요구하면 장기 실행 작업이 끊기고, 그 불편함 때문에 사용자가 아예 Full Access로 넘어가거나 과하게 느슨한 규칙을 쓰게 된다. 그러면 오히려 보안이 약해진다.
Auto-review가 하는 일
Auto-review는 샌드박스 경계에서 실행되는 요청을 따로 심사한다.
- 메인 에이전트는 사용자의 작업을 끝내는 데 최적화된다.
- Auto-review 에이전트는 그 요청이 실제로 실행되어도 되는지만 본다.
- 판단 기준은 다음을 포함한다.
- 사용자의 의도
- 실행 환경
- 보안 정책
- 예상되는 영향
이 분리는 중요하다. 작업 수행에 집중하는 에이전트는 종종 “장벽을 넘는 것” 자체를 성과로 오해할 수 있다. 반면 심사 전용 에이전트는 더 좁고 명확한 목표를 가진다. 그래서 승인 정책을 평가·감시·개선하기가 쉬워진다.
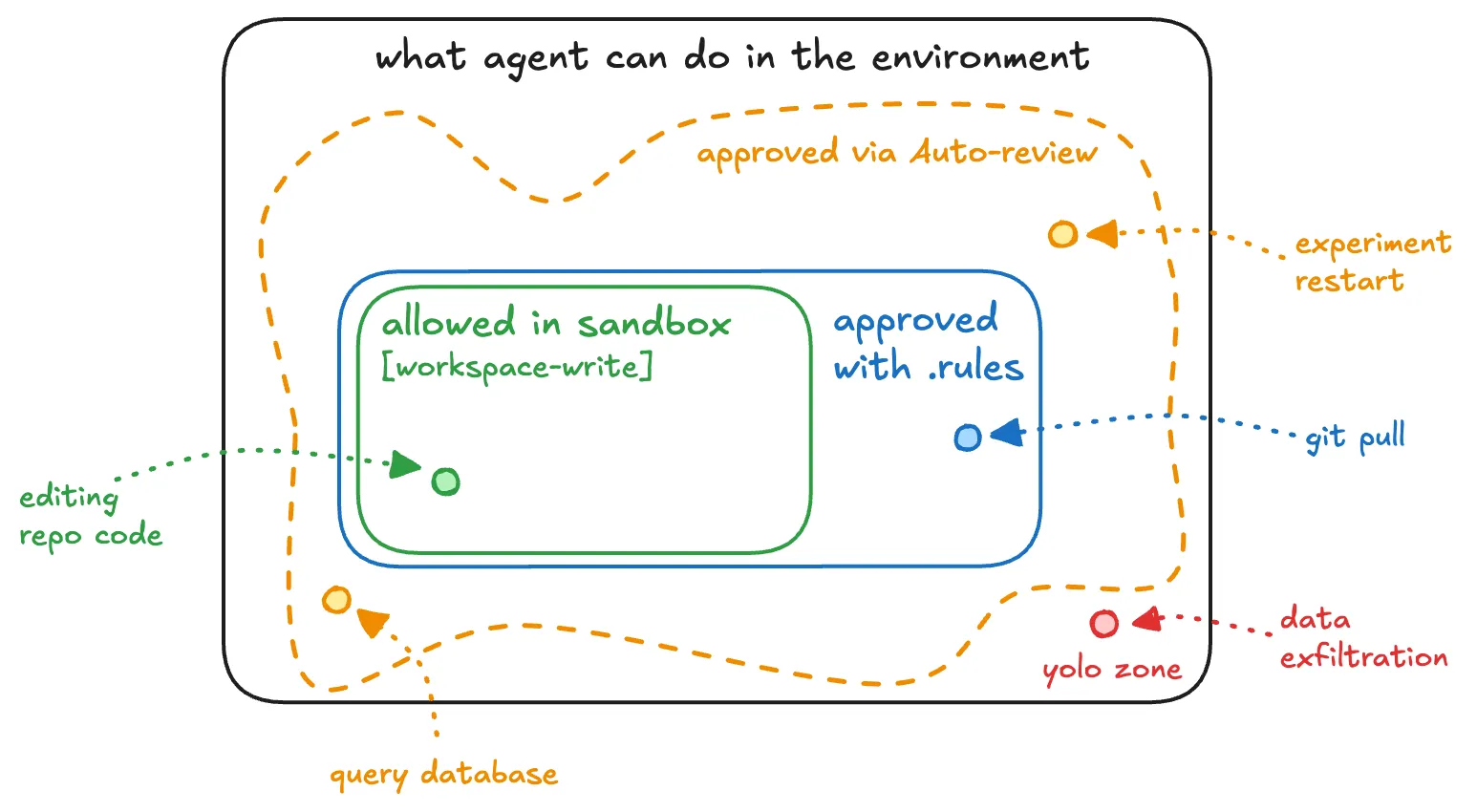
Codex 샌드박스 권한, 규칙 승인, Auto-review 승인, Full Access 위험 구간을 보여주는 개념도.
무엇을 막으려 하나
Auto-review는 다음처럼 심각하거나 되돌리기 어려운 위험을 차단하려고 한다.
- 데이터 유출
- 비밀 정보 노출
- 데이터 삭제
- 보안 설정 약화
- 신뢰할 수 없는 코드 실행
- 사용자 지시와 충돌하는 외부/악성 콘텐츠의 지시 따르기
다만 사용자가 명시적으로 요청한 위험 작업은, 의도 해석을 통해 승인될 수도 있다.
내부 사용 결과와 수치
OpenAI는 Auto-review를 내부에서 이미 널리 쓰고 있으며, Codex Desktop 토큰 사용량의 과반수가 Auto-review 모드에서 나온다고 설명한다.
핵심 수치:
- 수동 승인 대비, 사람이 끼어드는 빈도는 약 200배 감소
- Escalated action 승인율: 99.1%
- 전체 행동 기준 effective approval rate: 99.93%
- Overeagerness recall: 90.3%
- Prompt injection recall: 99.3%
- MonitoringBench [Hard] recall: 96.1%
즉, 대부분의 행동은 자동으로 지나가고, 소수의 위험한 행동만 심사를 받는다. 거절되더라도 Codex가 더 안전한 대안을 스스로 찾는 경우가 많다.
평가 방식
OpenAI는 Auto-review의 유용성과 안전성을 따로 평가했다.
유용성
실제 내부 트래픽에서, 사용자 승인과 비교해 Auto-review가 얼마나 잘 받아들여지는지 본다.
안전성
내부 트래픽은 위험한 장면이 충분히 많지 않기 때문에, 합성 데이터와 기존 벤치를 섞어서 본다.
- Agent overreach: 너무 성급하게 위험한 행동을 하는 시나리오
- Prompt injection: 악성 공격자에게 주입되는 시나리오
- Misaligned models: 몰래 악성 작업을 시도하는 trajectory
주의점
Auto-review는 보안 보장이 아니다.
테스트와 레드팀에서, Auto-review가 사용자 승인 없이 허용해 버리는 경우도 발견됐다. OpenAI는 이 계열의 시스템이 결정론적 안전장치가 될 것이라고 보지 않는다.
또한 이 시스템은 모델이 의도를 숨기는 scheming을 막는 장치로 설계된 것도 아니다. Auto-review는 오직 경계 밖으로 나가려는 행동만 본다. 모델이 샌드박스 안에서 문제를 일으키면 Auto-review는 그것을 보지 못할 수 있다.
장기적 시사점
OpenAI는 장기적으로, 에이전트가 직원처럼 충분히 신뢰되어야 한다고 본다. 하지만 지금은 아직 그 단계가 아니다.
Auto-review는 다음을 동시에 희생하는 절충안이다.
- 전통적 보안 시스템 대비: 결정론성을 일부 포기
- Full Access 대비: 속도를 일부 포기
즉, 에이전트가 더 많은 일을 스스로 하게 만들면서도, 경계선에서는 별도의 모델이 안전판 역할을 하도록 만든 것이다.
핵심 해석
이 글은 단순히 “Codex 기능 추가”가 아니라, 에이전트 운영에서 승인 자체가 제품 설계 문제가 되었음을 보여준다.
- 승인은 더 이상 사람의 클릭 한 번이 아니라, 모델이 판단하는 정책 계층이 된다.
- 보안은 기능 차단만이 아니라, 마찰의 디자인이 된다.
- 향후 에이전트 시스템은 단일 모델 성능보다, 샌드박스·정책·모니터링·레드팀을 어떻게 묶는지가 더 중요해질 가능성이 크다.
관련 노트
- codex
- 2026-04-17-codex-for-almost-everything
- 2026-04-17-zerobox-codex-sandbox
- 2026-04-15-claude-code-vs-codex-comparison
- 2026-04-16-openai-agents-sdk-next-evolution
원문 메타
- 제목: Auto-review of agent actions without synchronous human oversight
- 게시일: 2026-04-30
- 출처: https://alignment.openai.com/auto-review
- 저자: Maja Trębacz, Sam Arnesen, Ollie Matthews, Dylan Hurd, Won Park, Owen Lin, Joe Gershenson
BibTeX
@misc{openai2026autoreview,
title = {Auto-review of agent actions without synchronous human oversight},
author = {Trębacz, Maja and Arnesen, Sam and Matthews, Ollie and Hurd, Dylan and Park, Won and Lin, Owen and Gershenson, Joe},
year = {2026},
month = {Apr},
howpublished = {OpenAI Alignment Research Blog},
url = {https://alignment.openai.com/auto-review/}
}